This section contains detailed guides for working with HEIR.
1 - Adding a new backend
This document describes the steps and considerations for adding a new backend to HEIR.
Overview
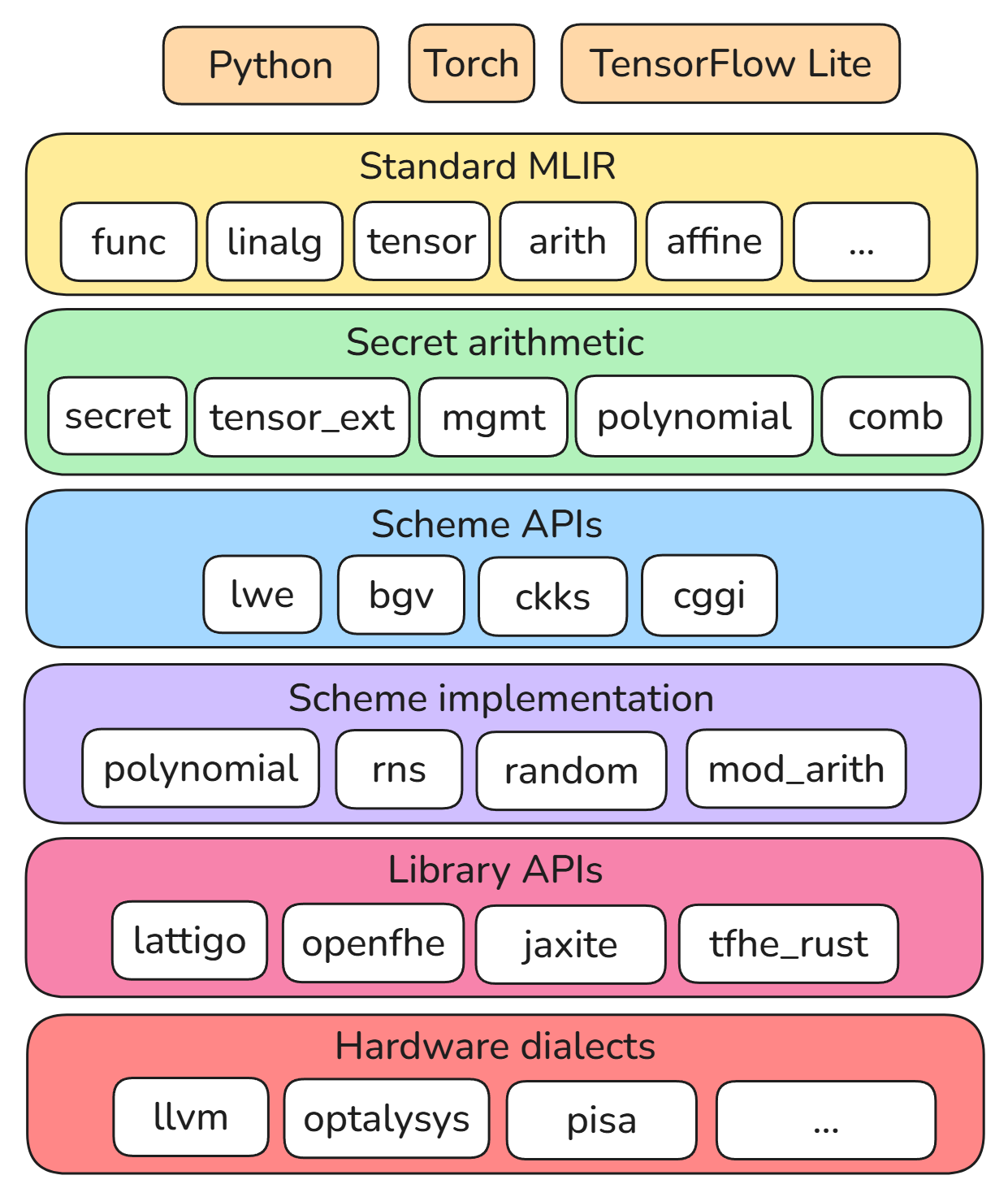
HEIR’s design involves multiple layers of abstraction called dialects. Dialects are roughly grouped into layers, and HEIR support importing or exporting a program at any layer.
To add a new backend to HEIR, you must first decide what layer of abstraction in the HEIR compilation stack corresponds most closely to the entry point of your backend’s toolchain. The most common examples are:
- A software library whose API corresponds to FHE scheme operations such as
ciphertext-ciphertext multiplication, slot rotation, and bootstrapping.
OpenFHE, Lattigo, and
tfhe-rsare examples of this kind of backend. - A software library whose API has additional high-level operations like
ciphertext-ciphertext matrix multiplication that must be preserved in order
to utilize dedicated kernels implemented in the library. This may occur in,
say, a GPU backend implemented in CUDA, but it also applies to software
libraries like OpenFHE, which have optimized APIs for operations like
LinearTranform. - A hardware backend that has an input IR and an additional toolchain that compiles the input IR down to the hardware’s assembly language. This is common in many accelerator efforts, and integration layers like the FHETCH IR.
We will cover the details of each option above in sections below. However, note that option (1) will have many details about dialect design and code generation process that are relevant to (2) and (3).
All code references in this document are pinned to the commit 980e96619bbcd312a107867ea9a19be653ec3af2, dated 2026-04-17.
Software library with a common scheme API
In this scenario, the backend corresponds to a software implementation of one or more FHE schemes, OpenFHE or Lattigo. In the dialect diagram, this would roughly correspond to the following path through HEIR. We will use the Lattigo software library as an example throughout this section.
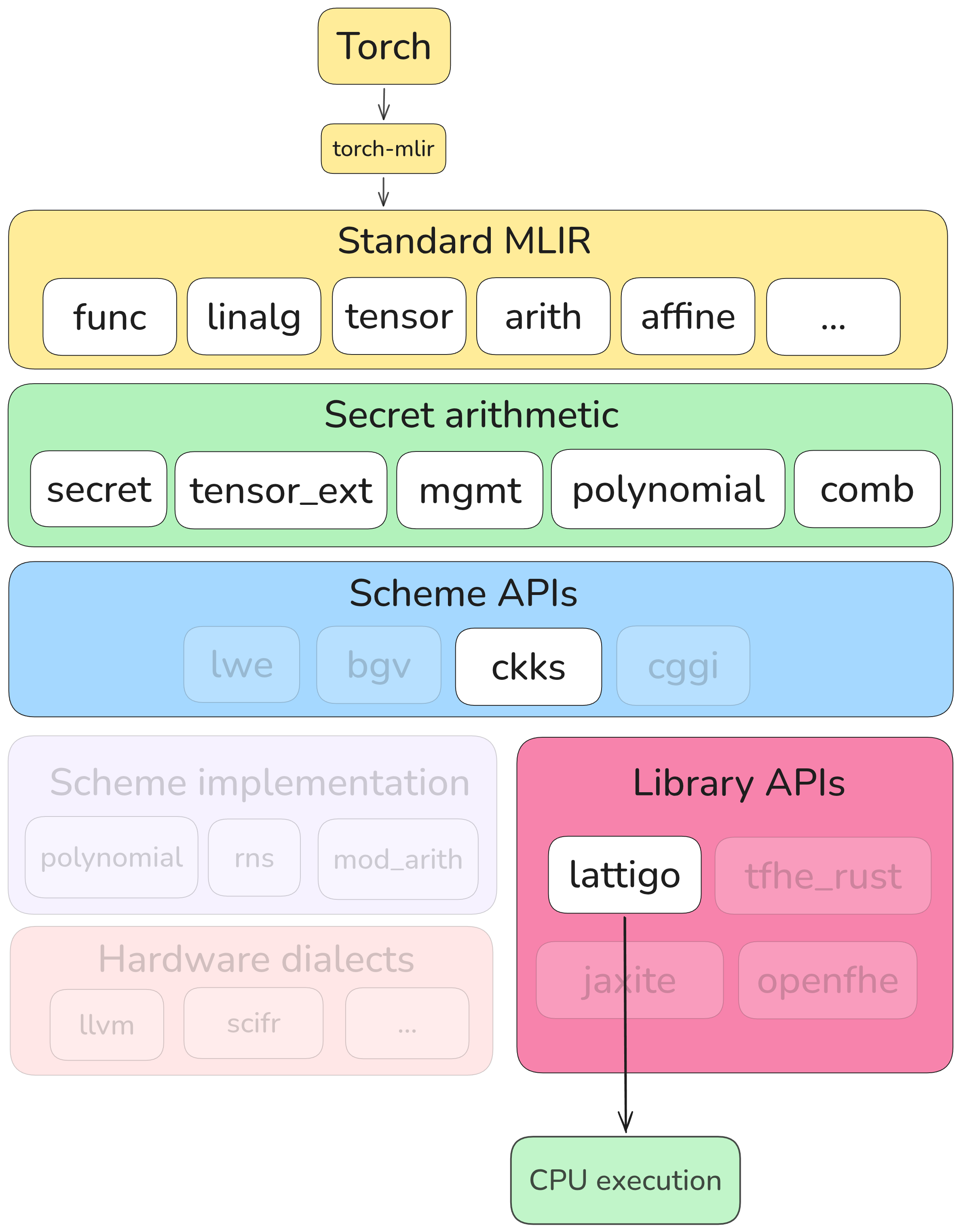
Supporting a new backend has the following components.
- Define a new exit dialect for the backend library, which should be as close
to an API mirror of the backend API as possible. For Lattigo it’s the
lattigodialect. - Add code-generation to the
heir-translatetool which generates source code for the backend API calls and wraps it into a module appropriately to the target language. For Lattigo this code is defined inlib/Target/Lattigo. - Add a lowering from the appropriate scheme dialect (e.g.,
ckks) to the exit dialect defined in (1). For Lattigo this pass islwe-to-lattigo. (it supports BGV/BFV and CKKS in the same pass). - Add any backend-specific optimizations to occur in the exit dialect. For example, the Lattigo exit dialect has transforms that handle configuring the backend and converting value-semantic operations to use Lattigo’s in-place API for improved efficiency.
- Add a new pipeline that combines the lowering and exit-dialect passes. For
example, Lattigo’s corresponding pipeline is defined
here.
Register the new pipeline with
heir-opt. - Add end-to-end tests of the new backend. For example, Lattigo’s end-to-end tests are here.
Each of the above parts is covered in more detail in subsections below.
New exit dialect
An “exit” dialect in MLIR represents the exit point from the MLIR ecosystem. Exit dialects, while still MLIR, are dictated by an external specifications like instruction set architectures or, software APIs beyond the scope of HEIR.
When defining an exit dialect for a HEIR software backend, the goal is to be as close to the external software API as possible, so that there is no complicated logic in the code generation process. All such logic should be moved to optimization passes and lowerings. There are some violations of this rule in the current HEIR codebase, for example in the handling of multi-dimensional tensors and memrefs, so ask the maintainers if you are unsure of some detail.
When defining a dialect one should introduce new types corresponding to the ciphertexts and plaintext types of the backend, as well as new types for any helper classes used by the backend when those types materialize as operands to various operations. For example, OpenFHE has a CryptoContext object and homomorphic operations are methods on that object; the IR must include it as a typed SSA value.
Compile time constants generally become MLIR attributes, and this can include
static values passed to configuration routines, such as the set of rotation
offsets required by the program (see RotationAnalysis).
A new dialect’s syntax should be tested using lit and FileCheck, with an
example
here
for Lattigo. Note that these tests are primarily designed to help you ensure you
got the Tablegen syntax correct and that the dialect is properly registered in
heir-opt.
To create the boilerplate for a new “dialect”, see templates.py.
For tips on defining an MLIR dialect, see Articles 3 and 4 of Jeremy Kun’s MLIR tutorial.
Codegen
The heir-translate binary encapsulates all
backend code generation routines in one binary for use in testing. These
routines generate source code in the target language with API calls against a
particular software library. For example heir-translate --emit-lattigo emits
Golang code against the Lattigo API, and this is defined in
lib/Target/Lattigo.
In most cases, code generation involves printing strings to an output stream. In
some cases, like C/C++ codegen, you can use the
emitc dialect from MLIR, which
itself is an exit dialect and code-generator for general-purpose C/C++ programs.
Then the particular emitc code generated can use the emitc.opaque type to
represent externally defined types and emitc.call_opaque to represent function
calls.
There is currently no emitpython, emitrust or emitgo dialect, but if we
have enough repetitive codegen, it might be worth it for us to make such a
dialect.
The process of generating source code is admittedly laborious. One might wonder why we don’t interpret HEIR’s exit dialect directly. In fact, we can (see, for example, the OpenFHE interpreter). However, this has a negative impact on performance, and requires added maintenance of the interpreter code. And finally, to use the interpreter you must have a dependency on HEIR itself, at least for the MLIR parser. By contrast, generated source code can be completely removed from HEIR and recompiled in isolation, enabling further customization and easier integration.
The codegen should be tested using lit and FileCheck, with an example
here
for Lattigo.
Lowering from scheme to backend
Define a dialect conversion pass that starts from your desired scheme dialect
(such as ckks or cggi) and converts the types and ops to the exit dialect.
One potentially difficult aspect of this is in parameter selection. In the HEIR
scheme dialects, parameters have been selected by earlier passes. Sometimes
these passes must depend on the details of the target backend. Cf.
#2554 for more on that. And
sometimes a backend is not possible to configure with the same level of
granularity that a compiler can offer. For example, OpenFHE does not support
setting the exact primes used for RNS limb moduli, and tfhe-rs offers only a
pre-determined set of parameters.
In some cases, this means that HEIR’s parameter selection is simply ignored, and
the backend is left to make up the difference (e.g., with automatic scale
management vs scale management pre-scheduled by HEIR). In these cases, the
scheme-to-backend lowering may lose information as lwe types with rich
structure are replaced by opaque types.
The other main complexity is that scheme ops are split between the lwe
dialect, which covers ops common to more than one FHE scheme, and
scheme-specific dialects (like ckks, bgv, and cggi) where the semantics of
the op differs from scheme to scheme.
An example lowering is
lwe-to-lattigo.
For tips on dialect conversion, see Article 10 of Jeremy Kun’s MLIR tutorial.
Backend-specific passes
Depending on the backend, you may need to define a set of backend-specific passes that can only run on the exit dialect because the concepts do not exist at higher-level layers of abstraction.
For example, the lattigo dialect has a concept of in-place CKKS operations
vesus ops that allocate a new ciphertext as the return value. These APIs ask you
provide (as a separate operand) the ciphertext you would like to use for
storage. As such, the
lattigo-alloc-to-inplace pass must
operate on lattigo dialect IR.
More generally, each backend typically has a configuration pass that analyzes the IR as needed and inserts new functions that call the backend API to do things like generate key material, enable/disable bootstrapping, and set security parameters.
To create the boilerplate for a new “dialect transform”, see templates.py.
For tips on writing an MLIR pass, see Articles 3 and 4 of Jeremy Kun’s MLIR tutorial.
New pipeline
Pipelines are defined in
lib/Pipelines
and can be defined to have a configuration options (PassOptions::Option) that
materialize as command-line flags when
registered
on heir-opt.
The pipeline can consist of an arbitrary set of passes, but usually there is a phase of lowering from scheme to backend, a phase of optimizing or configuring in the backend dialect itself, and then general-purpose passes like dead code elimination or common subexpression elimination.
And example Lattigo pipeline is here
End-to-end (e2e) testing
Each of the above steps should be tested with lit and FileCheck testing.
However, those testing methods assert the output IR from the compiler matches
expectations; it does not run the generated code and check that for correctness
or performance.
So we ask each backend have an added layer of testing that runs the full
heir-opt + heir-translate pipeline, compiles the resulting generated code
against the backend, and then runs it on a given input and asserts something
about the output.
We will use the Lattigo + CKKS example
dot_product_8f
as a simple e2e test to outline the components.
load("@heir//tests/Examples/lattigo:test.bzl", "heir_lattigo_lib")
load("@rules_go//go:def.bzl", "go_test")
package(default_applicable_licenses = ["@heir//:license"])
heir_lattigo_lib(
name = "dot_product_8f",
go_library_name = "dotproduct8f",
heir_opt_flags = [
"--annotate-module=backend=lattigo scheme=ckks",
"--mlir-to-ckks=ciphertext-degree=2048 first-mod-bits=0",
"--scheme-to-lattigo",
],
mlir_src = "@heir//tests/Examples/common:dot_product_8f.mlir",
)
go_test(
name = "dotproduct8f_test",
srcs = ["dot_product_8f_test.go"],
embed = [":dotproduct8f"],
)
First, the build file imports a bazel macro heir_lattigo_lib, which is a
shared helper for all Lattigo e2e tests. It handles composing heir-opt and
heir-translate to produce a packaged go_library target with all the
appropriate Lattigo dependencies included, and this target can be depended on by
a main harness that runs the compiled functions.
To view code generated by the bazel macro, build
bazel build //tests/Examples/lattigo/ckks/dot_product_8f:all
Then you can view the generated code in this path (relative to the root of the git repo).
bazel-bin/tests/Examples/lattigo/ckks/dot_product_8f/dotproduct8f_lib.go
For example, you can see the exact function signatures to help write a test harness.
$ rg func bazel-bin/tests/Examples/lattigo/ckks/dot_product_8f/dotproduct8f_lib.go
9:func dot_product(evaluator *ckks.Evaluator, param ckks.Parameters, encoder *ckks.Encoder, v0 []*rlwe.Ciphertext, v1 []*rlwe.Ciphertext) ([]*rlwe.Ciphertext) {
152:func dot_product__encrypt__arg0(_ *ckks.Evaluator, param ckks.Parameters, encoder *ckks.Encoder, encryptor *rlwe.Encryptor, v0 []float32) ([]*rlwe.Ciphertext) {
186:func dot_product__encrypt__arg1(_ *ckks.Evaluator, param ckks.Parameters, encoder *ckks.Encoder, encryptor *rlwe.Encryptor, v0 []float32) ([]*rlwe.Ciphertext) {
220:func dot_product__decrypt__result0(_ *ckks.Evaluator, _ ckks.Parameters, encoder *ckks.Encoder, decryptor *rlwe.Decryptor, v0 []*rlwe.Ciphertext) (float32) {
235:func dot_product__configure() (*ckks.Evaluator, ckks.Parameters, *ckks.Encoder, *rlwe.Encryptor, *rlwe.Decryptor) {
This test harness in this case is
package dotproduct8f
import (
"math"
"testing"
)
func TestBinops(t *testing.T) {
evaluator, params, ecd, enc, dec := dot_product__configure()
arg0 := []float32{0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8}
arg1 := []float32{0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}
expected := float32(2.50)
ct0 := dot_product__encrypt__arg0(evaluator, params, ecd, enc, arg0)
ct1 := dot_product__encrypt__arg1(evaluator, params, ecd, enc, arg1)
resultCt := dot_product(evaluator, params, ecd, ct0, ct1)
result := dot_product__decrypt__result0(evaluator, params, ecd, dec, resultCt)
errorThreshold := float64(0.0001)
if math.Abs(float64(result-expected)) > errorThreshold {
t.Errorf("Decryption error %.2f != %.2f", result, expected)
}
}
Then test it with bazel test //tests/Examples/lattigo/ckks/dot_product_8f:all.
For testing performance, you will want to run this with -c opt to ensure
Lattigo itself is compiled with optimizations, but noting from the
bazel tips page, switching between -c opt and
-c dbg can incur rebuilds of LLVM, so use it with care.
Adding the new backend library as a project dependency
In order to support e2e tests of a new backend, that backend needs to be
compiled from source and added as a HEIR dependency in MODULE.bazel. The
method for doing this depends on the language.
- C++: The source must be packaged up and released on the Bazel Central Registry, and a bazel overlay must be added to support bazel integration if the project does not have its own bazel integration. See for example OpenFHE. Ask j2kun for help with this if you need it.
- Python: The package must be available on PyPI and added to the
project.optional-dependenciessection ofpyproject.toml. Jaxite is integrated this way. - Go: The package must be available on golang’s standard package manager, and
added to
go.mod. Lattigo is integrated this way. - Rust: The package must be available on crates.io and a
crate.speccall added toModule.bazel.tfhe-rsis integrated this way.
Additionally, any libraries required for defining a harness or using the
compiled code need to be added in the same way. For example, HEIR’s generated
code for tfhe-rs uses the rayon crate, so rayon must be added as a direct
dependency of HEIR.
If the library’s language is not among those above, reach out to the HEIR maintainers for advice.
Software library with special features
When adding support for a backend with a non-standard API, one must add or modify additional passes at earlier stages of the pipeline to support the special features of the backend.
For example, the software library may have special support for a
linear-algebraic operation like matrix multiplication. In this case, the earlier
stages of HEIR’s pipeline that lower linalg.matmul must be modified
appropriately, or replaced in the new pipeline with alternative passes.
The details of what needs to be done depend greatly on the feature itself. There are a few possible things that need to be considered:
- High-level ops that are preserved must be supported in lower levels as well.
For example, the default ciphertext management passes may not handle a
linalgop, and the right way to handle it necessarily depends on details about the backend. - Backends introducing new concepts (for example, a new CKKS scaling method) must have corresponding passes that analyze the IR as needed to support them. For example, as of 2026-04, high-precision scale management is not supported in HEIR, so one would need to add support for it if the backend required the user to specify specific, high-precision scaling factors.
- Backends whose internal implementation details differ significantly may require backend-specific configuration to be integrated into earlier passes. For example, the ciphertext management passes require knowledge of how many levels are consumed by the bootstrapping subroutine. That should be configurable in these passes by manual flags.
The ideal method to inform passes about backend-specific metadata is by having a separate interface layer that allows the pass to expose a minimal amount of information about the backend. As of 2026-04, this is still under active design and development. Cf. #2554 for more details.
Hardware backend with additional compiler toolchain
Hardware backends tend to be split into two camps for entrypoints to their compilation stack: having a published high level IR HEIR can target, and mirroring an existing software library API. For an existing library API, the case is identical to the software library code generation above.
Otherwise, the “high level IR” for a hardware target tends to be lower level
than FHE scheme APIs. In particular, they may be closest to HEIR’s polynomial,
mod_arith, and rns dialects.
In this case, the exit dialect likely would have its lowering start from the
polynomial dialect, with rns-of-mod_arith-typed coefficients. To support
that, the relevant FHE cryptosystem must be implemented as lowering passes in
HEIR. As of 2026, this is in various states of progress (Cf.
#2866 for CKKS).
After that, however, the process is similar to software library codegen: create an exit dialect mirroring the external IR, lower to it, run any special optimizations, and then generate code.
Backends for unsupported schemes
Some backend libraries may involve new FHE schemes not supported in HEIR.
Generally speaking, this implies adding a new scheme dialect alongside ckks,
bgv, and cggi. Depending on how much the new scheme deviates from HEIR’s
existing assumptions, this may require further changes to other dialects.
For example, HEIR’s polynomial dialect hard-codes univariate polynomial moduli,
so if the scheme uses a bivariate ring structure in a way the compiler needs to
know about, this will require nontrivial changes to polynomial. Another
example is RNS form. While HEIR’s current design supports not using rns, there
are likely some parts of the codebase that inadvertently assume rns form and
will require appropriate generalization.
In this case, please consult the HEIR maintainers for advice, and sketch out a design proposal.